

MongoDB and Mongoose - How Every Web Developer Can Become FullStack With Node.js
In the previous post about MERN Stack we developed a simple REST API with Node.js and Express, our fake database was a collection of JSON and there was no real interaction with a database, only with the filesystem.
In this post we will continue that project about companies and jobs by adding a real database into the mix, for that we will use MongoDB, check what relational and non-relational databases are, what packages to use to improve our developer experience and where and how to manage the database.
Example project
You can check the first entry of this series if you want to learn more about how Node.js and Express work or start right where we left off last time in this branch.
The example project is a fictitious project about companies posting jobs to work on Mars.
Why MongoDB?
I used JSON files in the previous post because the data structure is very similar on how document based databases work so, the transition from one to the other will be easier, but why use MongoDB instead of other databases?
The first reason is because it is the M in the MERN stack and what kind of MERN stack guide would it be if I dare to use another one!
The real reasons come when compared to traditional databases as we will see below. But in short, Mongo was created to address problems such as evolving applications quickly without database migrations and having data that is frequently read in the same place to increase performance.
Different concepts for different types of databases
In the following sections I will refer to traditional databases also known as SQL or relational databases such as MySQL or PostgreSQL and non-tabular databases such as MongoDB or Apache Cassandra.
*You will also see the definition of NoSQL or non-relational databases but it is partially incorrect because there are relationships, but not in the traditional way we know and there is also Structured Query Language in this kind of databases although it is not SQL, we will see both topics later.
Storing Data
Traditional database → The structure of the data is predefined and fixed, meaning that it stores the data in Tables which are defined by Columns.
*Document database → The structure is optional and flexible, the data is stored in Collections containing Documents, each Document can have the same fields, slightly different or totally different.
*I use the document database here as an example because we will use MongoDB in this guide, but NoSQL databases can be key-value, graph and wide-column oriented data, not just document oriented data.
So to summarise the evolution of these concepts a bit:
Table → Collection
Row → Document
Column → Field
Relations
Traditional database → This is done with a primary key column in one table and a foreign key column in the other table linking the relationship.
Document database → There are different ways to achieve this:
- The data contained in a
Documentis of JSON type so the direct way to achieve relationships is: embed data. - Create different
Collectionsand link theDocumentsby theirid, very similar to the SQL DB approach.
Embedding data
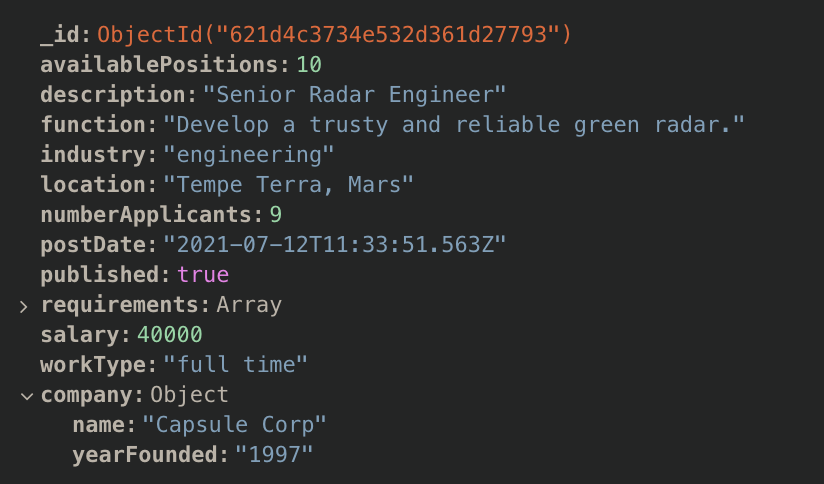
Here we have a Document on a Job that contains another scope of data relating to the Company in the same Document.
This approach is good when your document is small, if you are nesting large trees you may face performance issues at some point. It can also be used with things that don't have their own entity because when you want to update some value it can be a mess to go one by one making updates.
Relationship to id

As you can see this Document contains the information relating to the Job but it also has companyId which links this particular Document to another one in another Collection.
This approach is useful when you want to keep the scopes separate and for example update a field in a Document and all its relationships will get that single change without modifying anything.
Queries
Some examples of simple queries:
SELECT * FROM users WHERE username="dastasoft"
SELECT * FROM companies ORDER BY _id DESC
SELECT name, salary FROM jobs WHERE availablePositions > 10
db.users.find({username="dastasoft"})
db.companies.find().sort( { _id : -1 })
db.jobs.find({ availablePositions : {$gt: 10}}, { name : 1, salary : 1})
As I said before, MongoDB does not use SQL, but it has its own syntax to achieve the same behaviour.
As you can see, the type of database depends entirely on the needs and nature of your project, with traditional databases you need to do a lot of hard work beforehand to design the database and NoSQL databases are more suitable for projects that are unsure of the features they will have, the scale or the need to adapt quickly to changing requirements.
In short, there is no best option per se, it all depends on your needs.
Setup
If you want to use MongoDB as your database there are many options for where you can store your data. I'll just list a few options and give a brief description.
Install locally
Installing MongoDB on your machine may be one of the best options, especially if it is your first time using MongoDB, it is a good option to install locally and play around with it.
Docker
With the example project this option is provided, if you install Docker on your system you will be able to run a MongoDB instance without installing MongoDB itself, the best thing about this option is that it is highly portable and convenient, also this option tries to end the "on my local machine it works" quote because you will be able to deploy that same Docker container to a PROD environment.
The scope of this guide does not cover Docker stuff so, inside the example project you can check how the initial data is stored in the DB and the Docker related configuration but if you are not interested in that part, just run npm run start:docker.
MongoDB Atlas
Atlas is a multi-cloud database service from the creators of MongoDB, it is the most complete option because you don't have to install anything on your computer, you can choose from the major cloud providers to store your database and like many services nowadays you can start for free and pay as you go.
Also the database at the free level can be provisioned with sample data, one of my previous sample projects Apartmentfy was built entirely with sample data, check out the different sample collections and maybe your next project already has data ready to use.
MongoDB Shell, MongoDB for VS Code and Compass
Whichever installation option you chose, you'll need to check the data, and there are three options beyond checking the MongoDB Atlas web site if you chose that option.
If you have installed MongoDB on your machine, the MongoDB Shell is also installed, so you can connect to the database provided in the example project with:
mongo -port 27017 -u root -p password
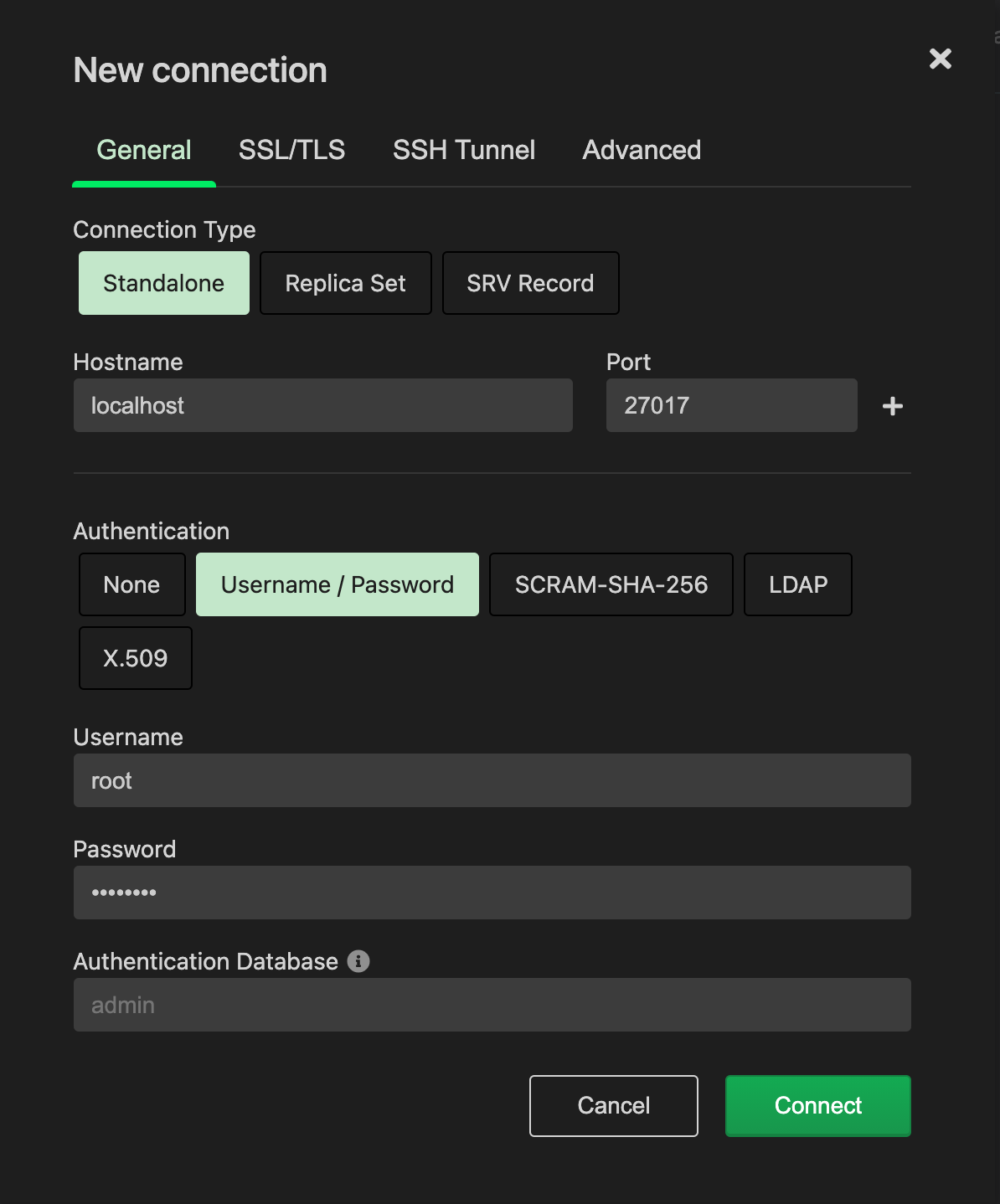
There is a MongoDB for VS Code plugin that will allow you to check data and test queries directly in VSCode, you will have to provide the connection string or fill in the form, for example to connect to the example project:
The other option is to install MondoDB Compass, a graphical interface that is very similar to what you will see on the MongoDB Atlas website.
Interacting with the DB from Node.js
The most basic way to interact with MongoDB is using the Official MongoDB Node.js Driver, in this guide we will use Mongoose an object modeling tool.
Before diving into Mongoose it is important to know why we choose one or the other. Mongoose is built on top of MongoDB Native Driver so, as you can imagine if you need more control or a more raw approach, Mongoose is an extra layer that you may not need.
While Mongoose is intended to allow developers to create and force specific schemas, validations and different utilities at the application layer, MongoDB Native Driver relies on the database layer.
This means that if you use Mongoose you will code very javascript-like relationships, validations and so on and that will only be alive in your Node.js, the database won't be aware of any of this.
With MongoDB Native Driver you will have full control of what you are doing, and the configuration, like validations, will be in the database itself.
There is no bad option here, but there is some rule of thumb for deciding which one to use:
- If your data structure is simple, chances are you don't need Mongoose.
- If your data structure is very undefined and will change a lot, not being tied to a schema, as Mongoose tries to do, may be good for you.
- If you want to take advantage of the built-in validations, optimisations and other functionalities instead of doing it yourself, Mongoose can be a time saver.
At the end of the day Mongoose has a lot of work already done for you, which is why it is the choice of many developers but both options have a lot of support and both will give you more knowledge about how MongoDB works but remember that the official support from the MongoDB team will only be for Native Driver.
My recommendation is to start with what you want and learn the basics, if you work best in a defined/limited schema, Mongoose will be more suitable for you, if you want to do simple testing and try different things quickly, Native Driver will be a better experience. When you have all the basics, reread this section, it will make a lot more sense with that knowledge.
Also after this guide, spend some time going through Native Driver to get a good understanding of what is going on under the hood and to be able to choose the one that best suits your project. The whole example project is straightforward and can be done perfectly well without Mongoose.
Connection
// lib/db.ts
import mongoose from 'mongoose'
export default async function connectDB() {
try {
const Mongoose = await mongoose.connect(`${process.env.MONGO_URI}`)
console.log(`💿 MongoDB Live: ${Mongoose.connection.host}`)
} catch (error) {
console.error(error)
process.exit(1)
}
}
Connecting to the database is simple, just provide the URL of the MongoDB, depending on the option you have selected to store your database this will change but it will more or less follow this syntax:
mongodb://USER:PASSWORD@localhost:PORT/DATABASE?authSource=admin
Because this string contains sensitive information it is highly recommended to use environment variables and not to upload env files to the repo to avoid leaks.
Models and Schemas
As we saw before, one of the features of Mongoose is to interact with the DB, that is done through Schemas and Models.
The Schema will be a mapping of a MongoDB collection, we will control the form of the documents through the Schema, with TypeScript we will even control more explicitly this part.

Models will be a representation of a document, and will provide us with the different built-in instance methods to perform the different operations we need. Later we can add our own methods to the Model to perform custom operations.
//models/job.ts
import { Schema, Model, model } from 'mongoose'
import { Job as JobProps } from '../types'
const JobSchema = new Schema<JobProps, Model<JobProps>>(
{
availablePositions: { type: Number, min: 1 },
companyId: { type: Schema.Types.ObjectId, ref: 'Company', required: true },
description: { type: String, required: true },
function: { type: String, required: true },
industry: { type: String, required: true },
location: { type: String, required: true },
numberApplicants: Number,
postDate: { type: Date, default: () => Date.now() },
published: { type: Boolean, required: true },
requirements: { type: [String], required: true },
salary: Number,
workType: { type: String, required: true },
},
{ timestamps: true }
)
const JobModel = model<JobProps>('Job', JobSchema)
export default JobModel
Let's take a look at the model of a Job:
- We create the
Schemabased on Mongoose, thanks to TypeScript we can ensure that the form of the Schema is according to the type we define for aJob. - Each property is defined at least with its type, if you need to specify more parameters, then you need to use the longer syntax. As you can see
companyIdis what we will use later to retrieve information about companies that are in a different collection. This relationship is done by defining therefattribute and the special type that MongoDB uses for internal idsObjectId. - Finally we create the
Modelbased on the Schema.
*Properties can be as simple as String, Number, Date etc. or more complex like a nested object. In the example above you can find a good range of different possibilities.
**You don't need to specify an _id for your Schema, Mongoose will add it automatically but, if you need to set manual ids, you can define it explicitly.
Validators
In some properties I have placed validators, like min or required, in addition to the built-in validations you can create your own, for example let's imagine we want the numberApplicants to never be greater than the availablePositions.
numberApplicants: {
type: Number,
validate: {
validator: value => value <= this.availablePositions,
message: props =>
`${props.value} is higher than the available positions`,
},
}
Both built-in and custom validations will be executed ONLY when the save or create methods are performed on the model as we will see below.
In the User model you can see more examples of validators.
// models/user.ts
const UserSchema = new Schema<UserDocument, UserModel>(
{
avatar: String,
email: {
type: String,
required: true,
lowercase: true,
trim: true,
unique: true,
},
firstName: { type: String, required: true },
lastName: String,
password: { type: String, required: true, minlength: 8 },
type: {
type: String,
enum: ['applicant', 'recruiter'],
default: 'applicant',
},
username: {
type: String,
required: true,
unique: true,
minlength: 6,
maxLength: 24,
},
},
{ timestamps: true }
)
The timestamps you can check in both examples are to specify that we want the fields automatically createdAt and updatedAt.
So all this configuration gives us two things:
- Even before we run the project, we have type safety with TS.
- At runtime, if we mistakenly send a String to
availablePositionsor any other error that fails validations, we get a Mongoose error preventing that action.
Due to the nature of MongoDB and JS, each document may be different, without Mongoose or TS we may end up with a collection of these example documents
{
name: "Capsule Corp",
about: "Like WinRAR but we accept more file extensions.",
industries: ["automobile", "house", "engineering"],
numberEmployees: 2,
yearFounded: 1990,
someImportantProperty: "If I'm empty all explodes"
},
{
name: "Red Ribbon",
about: "We deliver the best Android you can ever had",
industries: ["militar", "artificial intelligence", "engineering"],
numberEmployees: '2000', // In this example this field is an string
yearFounded: 1000,
},
If this is not what is intended, finding these errors in a database with large documents can be a daunting task.
Controller
In the previous version of the example project all the communication was with a fake database made with JSON files but, the basic actions will remain the same, we will list, create, update and delete, this time, we will be using the Model we created in the previous step to interact with MongoDB.
// controllers/job.ts
import { Request, Response } from 'express'
import JobModel from '../models/job'
import { Company } from '../types'
const list = async (req: Request, res: Response) => {
try {
const job = await JobModel.find()
.populate<{ companyId: Company }>('companyId')
.sort({
createdAt: -1,
})
res.json(job)
} catch (error) {
res.status(500).json({ error, message: 'No jobs were found.' })
}
}
const create = async (req: Request, res: Response) => {
if (!req.body) res.status(400).json({ message: 'No job has provided' })
try {
const job = await JobModel.create(req.body)
res.status(201).json(job)
} catch (error) {
res.status(500).json({ error, message: 'Error creating the job' })
}
}
const details = async (req: Request, res: Response) => {
const { id } = req.params
try {
const job = await JobModel.findById(id)
if (!job)
res.status(404).json({ message: `No jobs were found with id ${id}` })
res.status(200).json(job)
} catch (error) {
res.status(500).json({ error, message: 'Error retrieving the job' })
}
}
const update = async (req: Request, res: Response) => {
const { id } = req.params
try {
const job = await JobModel.findByIdAndUpdate(id, req.body, {
useFindAndModify: true,
})
if (!job)
res.status(404).json({
message: `Cannot update Job with id ${id}. Job was not found.`,
})
res.status(200).json(job)
} catch (error) {
res.status(500).json({
error,
message: `Error updating Job with id ${id}.`,
})
}
}
const remove = async (req: Request, res: Response) => {
const { id } = req.params
try {
const job = await JobModel.findByIdAndRemove(id)
if (!job)
res.status(404).json({
message: `Cannot delete Job with id ${id}. Job was not found.`,
})
res.status(200).json(job)
} catch (error) {
res.status(500).json({
error,
message: `Error deleting Job with id ${id}.`,
})
}
}
export { list, create, details, update, remove }
*This version it is also done with async/await instead of using callbacks as in the previous version of this tutorial to show a different version.
As you can see in the different methods, we use the Model which provides a lot of functionality to perform all the actions in a clear way.
Some of the basic functionalities are:
Retrieve data
find to retrieve all documents that pass the filter, in the example there is no filter but the method accepts an object to be used as a filter:
// find all documents in job collection that are from the electronics
// industry and have 100 or more available positions
JobModel.find({industry: "electronics", availablePositions: { $gte: 100 }})
You can query the data using regular expressions, exact numbers and many other combinations that give you a lot of flexibility.
Another way to query the data is to use where:
// Find jobs that...
JobModel.where("published").equals(true) // are published
JobModel.where("availablePositions").gt(1) // Has more than 1 available position
You can also chain multiple conditions as in the example above.
JobModel.where('industry')
.equals('electronics')
.where('availablePositions')
.gte(100)
Two important utilities for data retrieval are limit and select:
JobModel.where('industry')
.equals('electronics')
.where('availablePositions')
.gte(100)
.limit(10)
.select("description")
limitwill set a maximum number of results returned.selectwill return only that field for each document retrieved (plus the_id)
Joining documents
In the Job schema we have defined there is a reference to the Company schema with the companyId field. Each job will have a company that posts the actual job, what if I want to retrieve information about the company along with the job?
There are several ways to achieve this behaviour, one of which is included in the above example from the Controller, using populate.
JobModel.find().populate<{ companyId: Company }>("companyId")
With this, we are telling Mongoose that we want the Company information that is bound by the companyId field. The square brackets are part of TS specifying the type of object it will return, in this case a Company.
It is also worth mentioning that you can fill in certain parts of the other document instead of retrieving everything.
JobModel.find().populate("companyId", "name")
Save data
save to store new documents in the database, you can find an example in the create method in this example.
// req.body example data
// {
// availablePositions: 10,
// companyId: _id,
// description: "Senior Radar Engineer",
// function: "Develop a trusty and reliable green radar.",
// industry: "engineering",
// location: "Tempe Terra, Mars",
// numberApplicants: 9,
// postDate: "2021-07-12T11:33:51.563Z",
// published: true,
// requirements: [
// "At least three years of experience with Radar related hardware and Radar.js framework.",
// ],
// salary: 40000,
// workType: "full time",
// },
const job = new JobModel(req.body);
jobOffer.save().then(() => console.log("Job saved!"))
You can achieve the same behaviour in one step with create.
JobModel.create(req.body).then(() => console.log("Job offer saved!"))
Note that save is a method of the Model so you need to create an instance of that Model but create is a static method so you can use it directly.
Update data
The findByIdAndUpdate is a shortcut to perform both the search and the update, but remember that the update part will bypass the validators we defined in our Schema. If you want to run the validators using that function, you need to specify the runValidators option.
For example, let's imagine we put a min validator on numberEmployees in our company schema
// numberEmployees: { type: Number, required: true, min: 2 }
// req.body = { numberEmployees: 1}
const company = await CompanyModel.findByIdAndUpdate(id, req.body)
This will update correctly even if we have defined that min validator.
If you need the validators in this operation, you must explicitly specify it.
const company = await CompanyModel.findByIdAndUpdate(id, req.body, {
runValidators: true,
})
Also by default the document before the update is returned, if you need the updated document:
const company = await CompanyModel.findByIdAndUpdate(id, req.body, {
new: true
})
Remove data
Finally, findByIdAndRemove is like the above but for deletion purposes.
This is just a small number of examples of the methods that Mongoose provides.
Getting more from the schema
We now know the basics of how to perform CRUD operations with Mongoose, but there is more functionality available to go further with our Schema definition.
Schema methods
Apart from the built-in methods we can add our own custom logic to the schema.
For example in the user model we want to add a custom method to check if the password provided in the login is the same as the one we have in the database.
// models/user.ts
UserSchema.methods.isCorrectLogin = function (password: string) {
return new Promise<Error | boolean>((resolve, reject) => {
bcrypt.compare(password, this.password, function (err, result) {
if (err) return reject(err)
if (result) return resolve(true)
return resolve(false)
})
})
}
Custom methods will be used via the new keyword or after retrieving a Document never directly from the model.
// controllers/user.ts
const login = async (req: Request, res: Response) => {
if (!req.body) {
res.status(400).json({ message: 'No user data has been provided' })
}
const { email, password } = req.body
try {
const user = await UserModel.findOne({ email })
let isCorrectLogin: boolean | Error = false
if (user) {
isCorrectLogin = await user.isCorrectLogin(password)
if (isCorrectLogin)
res.status(200).json({ message: `Welcome ${user.fullName}` })
}
res.status(401).json({
message: 'Email password combination is not correct',
})
} catch (error) {
res.status(500).json({ error, message: 'Error retrieving the user' })
}
}
For TypeScript users, you will need to declare the following interface to bind properties, statics and custom methods to your schema.
//models/user.ts
interface UserDocument extends Document, UserProps {
isCorrectLogin(password: string): Promise<Error | boolean>
}
Schema Statics
If you need to use a custom functionality directly from the Model you can declare a static instead of a method.
// models/user.ts
UserSchema.statics.getUser = function (username: string) {
return new Promise((resolve, reject) => {
this.findOne({ username }, (err: Error, user: UserDocument) => {
if (err) reject(err)
resolve(user)
})
})
}
Note that this in this example refers to a user model and not to a user document as in the previous example.
For TS users, statics will be defined in the UserModel instead of the UserDocument.
// models/user.ts
interface UserModel extends Model<UserDocument> {
getUser(username: string): Promise<Error | UserDocument>
}
Both statics and methods must be declared using function and not with arrow functions, because arrow functions prevent linking this explicitly.
Virtual
In some cases properties are needed in the retrieved document but it may not be necessary to persist that data, the virtual are just for that.
Virtuals can be getters and setters, you will use getters when you need to combine data FROM the database and setters when you want to combine data WITHIN the database.
// models/user.ts
UserSchema.virtual('fullName').get(function (this: UserDocument) {
return this.firstName + this.lastName
})
For TS users, you will need to include these fields as UserDocument properties.
// models/user.ts
interface UserDocument extends Document, UserProps {
fullName: string
isCorrectLogin(password: string): Promise<Error | boolean>
}
Pre and Post Operations
Finally, if we want to execute something before or after a certain operation we can use the pre and post middlewares, for example in the sample project we encrypt the password provided by the user when perform singup
// models/user.ts
const ROUNDS = 10
UserSchema.pre<UserDocument>('save', async function (next) {
this.updatedAt = new Date()
if (this.isModified('password')) {
const hash = await bcrypt.hash(this.password, ROUNDS)
this.password = hash
}
next()
})
In this case, this will be executed before saving the user to the DB, we will take the password provided by the user, encrypt with bcrypt and modify the UserDocument to store.
Remember to use a regular function instead of an arrow function to preserve this as a UserDocument.
Conclusions
As you can see MongoDB is very flexible, and I hope you now understand a little more about its popularity, although here we have only scratched the surface of what MongoDB is capable of, I suggest you try this same exercise with the official MongoDB native driver just to expand your knowledge and really understand how it all works.
But the truth is that creating and maintaining a REST API can be a less daunting task with the help of Mongoose and through this article you have seen how to take advantage of its capabilities. In addition, we saw the basics of Express CRUD operations with MongoDB, why to use Mongoose or Native Driver and some TypeScript helpers.
From here you can try this same project with other databases beyond MongoDB, even relational databases, this project is now small enough to allow you to switch quickly and see the differences easily.